| home | library | feedback |
B-Course searches for certain kind of Bayesian network structures and certain kind of discretizations of the data.
» More about Bayesian network models
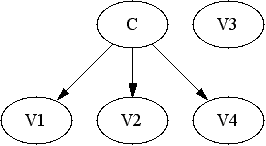
Here is a small example about Naive Bayes models. Let us assume that our data has a class variable C and predictor variables V1, V2, V3 and V4. The classical Naive Bayes model is a Bayesian network with arcs from C to all the predictor variables. B-Course also consideres models that have some solitary variables, that are not connected to anything. The connected nodes are those selected in variable selection.
The Naive Bayes model is not necessarily (even usually) a good model for the your data matrix, but because of its special form that connects all the predictors to the class variable, it is suited for classification. When this structure is interpreted as a dependency model, it says that all the predictors are dependent on the class variable (and vice versa since dependence is symmetric), but it also states that once we know the value of the class variable, all the predictor variables are independent of each other no matter what else we know or do not know. Now this may be true or false (usually latter) statement about your data, since there may quite well be variables in your data that are independent of the class variable. This is why we also search for Naive Bayes models where some of the arcs have been removed (leaving the predictors unconnected to anything like in the picture below).
One simple way to think about the Naive Bayes model is that we divide our data matrix to as many sub-matrices as there are classes in a data. We then proceed to build a separate model for each sub-matrix. These sub-models all have the most simple dependency model: none of them have any arcs thus stating that all the variables are independent of each other. The collection of these sub-models together with the knowledge of the sizes of classes equals the Naive Bayes model. Those familiar with the theory of predictive linear and quadratic discriminant analysis may notice that Naive Bayes resembles a simplified version of discriminant analysis where all the covariances are supposed to be zero.
» More about size of model space
» References to the material about Bayesian networks
So far we have talked about "variables" without any extra qualifications. However, B-Course will only use models for discrete data. Luckily this does not mean that we cannot use continuous data, since B-Course discretizes the data automatically.
» Read more about discretization
| B-Course, version 2.0.0 | |